AlphaMeet Eleven v3.
Meet Eleven v3.
The most expressive Text to Speech model.
Explore samples
Powered by Eleven v3 (alpha)
Control the emotion, delivery and direction with audio tags
Create controllable, expressive speech layered with emotion, audio events, and immersive soundscapes.

Generate dynamic conversations between multiple speakers
Create audio conversations where speakers share context and emotion, making generated dialogue sound natural and human.

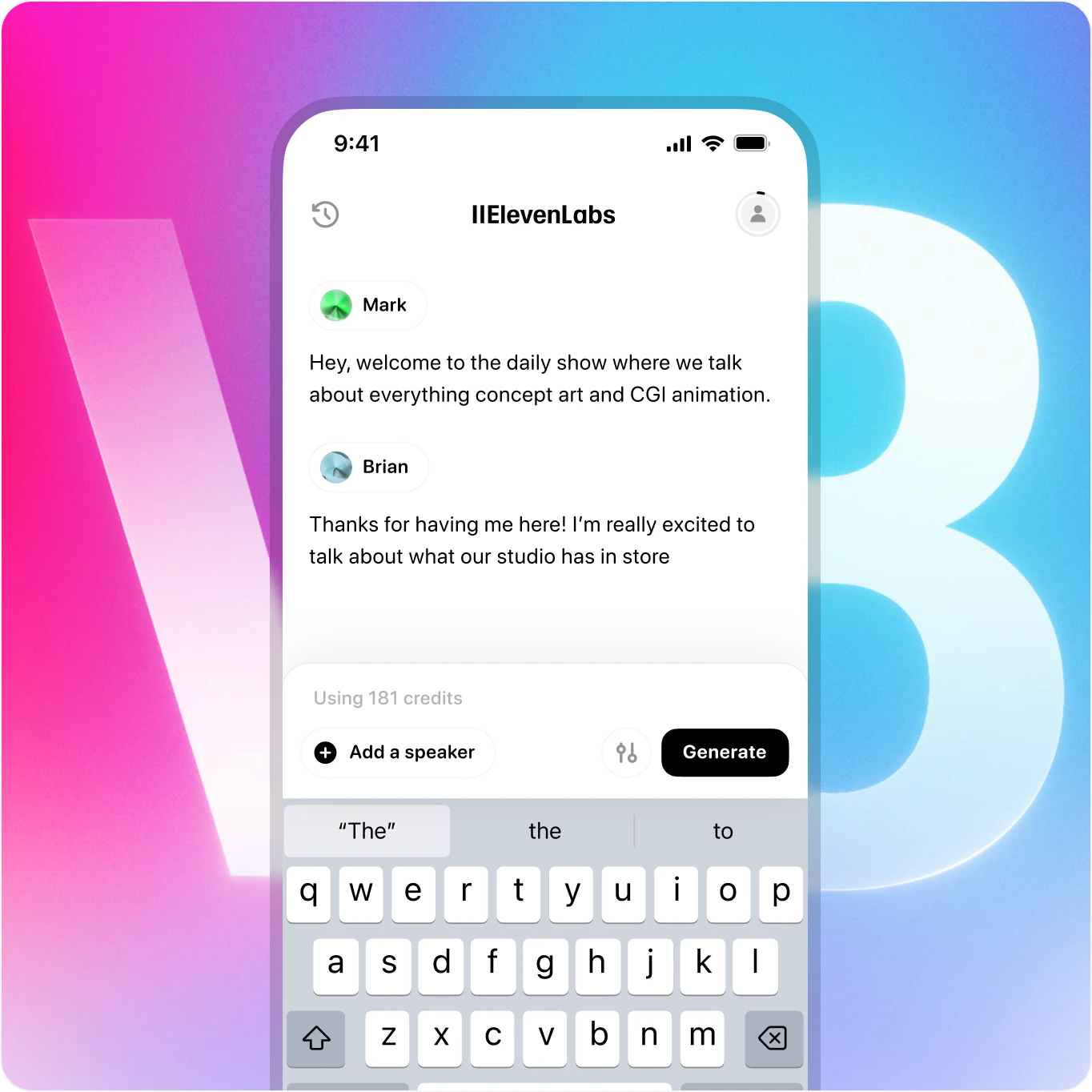
Take v3 anywhere - now available on mobile
Create lifelike speech with rich emotion - all from your phone. Our voice AI delivers studio-quality performance from anywhere.
Human-like speech in 70+ languages
Reach global audiences with expressive and nuanced speech in every major language.

English

Chinese

Spanish

French

Portuguese

German

Japanese

Italian
Experience our most expressive model with emotional depth and rich delivery.
Eleven v3 (alpha) is unlike other ElevenLabs models, offering a broad dynamic range controlled through inline audio tags.
Multiple speakers (Dialogue Mode)
Audio Tag Support
Full range of emotions, direction and audio effects
Basic tags like pauses and breaks
Languages
70+
29
Build with the Eleven v3 API
Generate lifelike speech in 70+ languages with emotion, direction, and multi-speaker control using inline audio tags.

| import { ElevenLabsClient, play } from '@elevenlabs/elevenlabs-js'; |
| import 'dotenv/config'; |
| const elevenlabs = new ElevenLabsClient(); |
| const voiceId = 'JBFqnCBsd6RMkjVDRZzb'; |
| const audio = await elevenlabs.textToSpeech.convert(voiceId, { |
| text: '[slowly] Back then... [chuckles] we had no phones. |
| [whispers] Just dirt roads and [coughs] big dreams. [sad] Then it happenend', |
| modelId: 'eleven_v3', |
| outputFormat: 'mp3_44100_128', |
| }); |
| await play(audio); |
They were generated with only the Eleven v3 model.
Text to Dialogue weaves multiple voices together to create a seamless interaction between them. Matching prosody, emotional range and taking cues from audio tags, Text to Dialogue is a leap forward in generating engaging conversations.
Public API for Eleven v3 (alpha) is now available. You may preview the eleven_v3 text to speech model capabilities here as well as its exclusive text to dialogue capabilities here.
Eleven v3 supports a wide variety of audio tags and are somewhat voice and context dependent. Read the prompting guide for further information.
Afrikaans (afr), Arabic (ara), Armenian (hye), Assamese (asm), Azerbaijani (aze), Belarusian (bel), Bengali (ben), Bosnian (bos), Bulgarian (bul), Catalan (cat), Cebuano (ceb), Chichewa (nya), Croatian (hrv), Czech (ces), Danish (dan), Dutch (nld), English (eng), Estonian (est), Filipino (fil), Finnish (fin), French (fra), Galician (glg), Georgian (kat), German (deu), Greek (ell), Gujarati (guj), Hausa (hau), Hebrew (heb), Hindi (hin), Hungarian (hun), Icelandic (isl), Indonesian (ind), Irish (gle), Italian (ita), Japanese (jpn), Javanese (jav), Kannada (kan), Kazakh (kaz), Kirghiz (kir), Korean (kor), Latvian (lav), Lingala (lin), Lithuanian (lit), Luxembourgish (ltz), Macedonian (mkd), Malay (msa), Malayalam (mal), Mandarin Chinese (cmn), Marathi (mar), Nepali (nep), Norwegian (nor), Pashto (pus), Persian (fas), Polish (pol), Portuguese (por), Punjabi (pan), Romanian (ron), Russian (rus), Serbian (srp), Sindhi (snd), Slovak (slk), Slovenian (slv), Somali (som), Spanish (spa), Swahili (swa), Swedish (swe), Tamil (tam), Telugu (tel), Thai (tha), Turkish (tur), Ukrainian (ukr), Urdu (urd), Vietnamese (vie), Welsh (cym)